
Microsoft is turning Microsoft 365 Copilot Researcher into a much more powerful deep research agent with new multi‑model features called Critique and Council. These upgrades aim to deliver research reports that are more accurate, more complete, and easier to trust for serious work.
Microsoft 365 Copilot Researcher gets multi‑model “Critique” and “Council”
In a new post on the Microsoft 365 Copilot Blog, Microsoft outlines how Researcher now uses multiple AI models instead of relying on a single system for everything. The company positions these changes as a major step toward higher‑quality, benchmark‑validated research output for complex tasks in enterprises and professional settings.
Researcher is described as a deep research agent built for “complex research in the flow of work,” and these new capabilities are designed to improve not just what answers you get, but how well those answers are sourced, evaluated, and presented. The two features—Critique and Council—approach that goal from different angles.
Critique: two-model system for deeper, cleaner research
Critique is a new multi‑model deep research pipeline that deliberately separates generation from evaluation. One model plans the task, runs retrieval, and drafts a full report; a second model then steps in as an expert reviewer, focused on strengthening quality rather than rewriting the work from scratch.

Microsoft says Critique uses models from “Frontier labs,” including Anthropic and OpenAI, and that this architecture outperforms traditional single‑model approaches on the DRACO benchmark (Deep Research Accuracy, Completeness, and Objectivity). Internally, Critique is driven by rubric‑based evaluation and focuses on three key dimensions:
-
Source reliability: Prioritizing reputable, domain‑appropriate, verifiable sources.
-
Report completeness: Ensuring the response fully addresses the user’s intent with relevant and unique insights.
-
Strict evidence grounding: Requiring key claims to be tightly tied to reliable sources and precise citations.
According to Microsoft, Critique becomes the default Researcher experience whenever users select “Auto” in the model picker, effectively making this two‑model architecture the standard path for deep research queries.
DRACO benchmark: big gains over single‑model systems
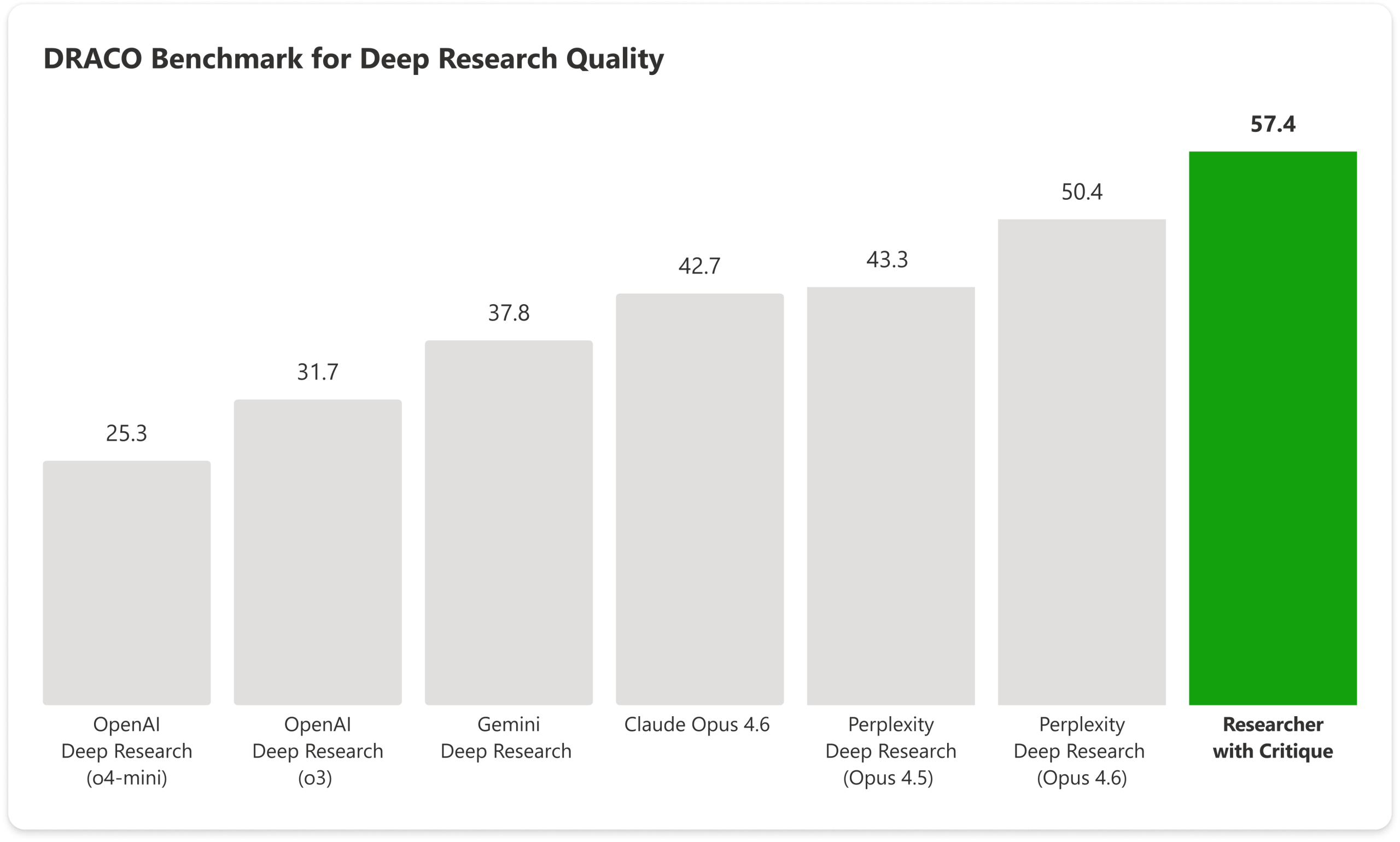
To validate Critique, Microsoft tested it on the DRACO benchmark—100 complex research tasks across 10 domains, originally introduced by researchers from Perplexity and academia earlier in 2026. All systems in DRACO are graded by OpenAI’s GPT‑5.2, which the benchmark paper identifies as the strictest of three judge models.
Using the same evaluation protocol and configuration as the original DRACO paper, Microsoft reports that Researcher with Critique delivers:
-
A +7.0 point gain on the aggregated DRACO score, amounting to a 13.88% improvement over Perplexity Deep Research (Claude Opus 4.6), the best system reported in the original benchmark.
-
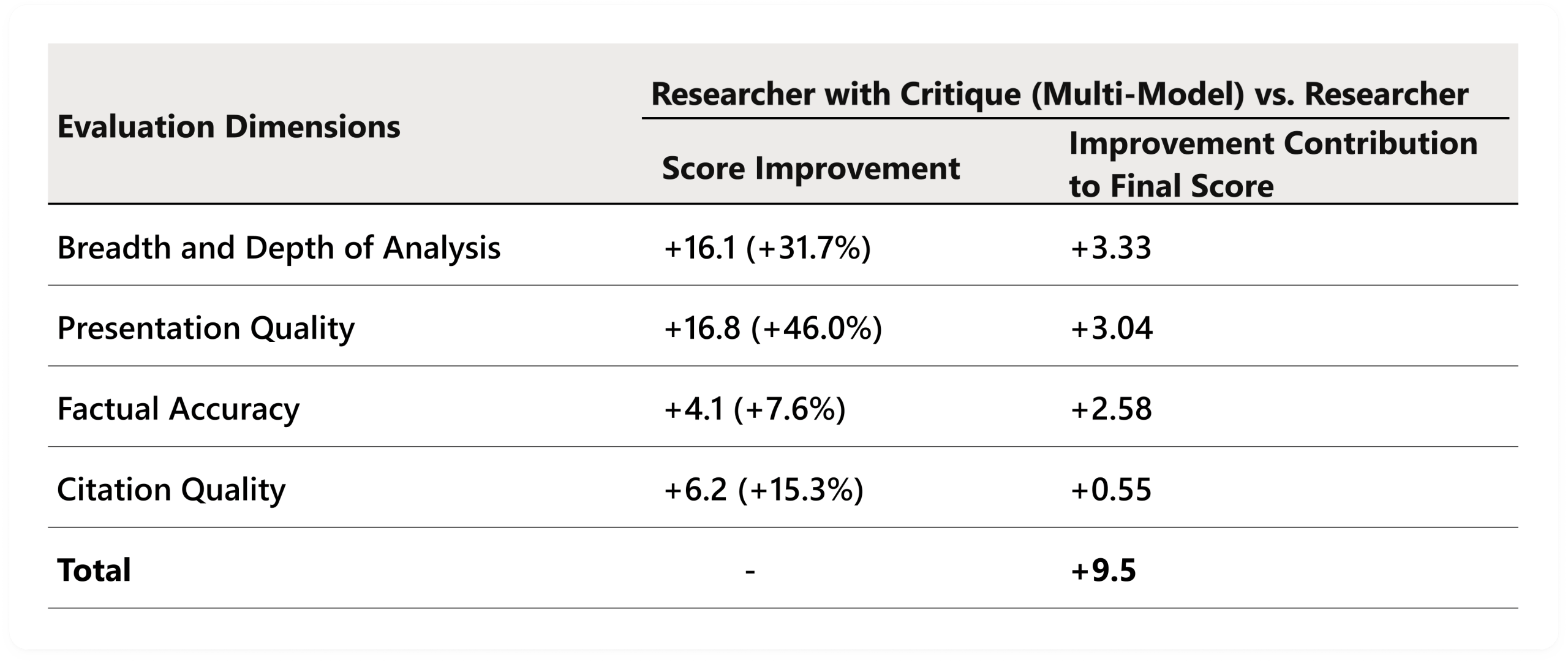
Statistically significant gains across all four DRACO dimensions: breadth and depth of analysis (+3.33), presentation quality (+3.04), and factual accuracy (+2.58), with citation quality also improving thanks to stricter grounding and better use of existing sources.
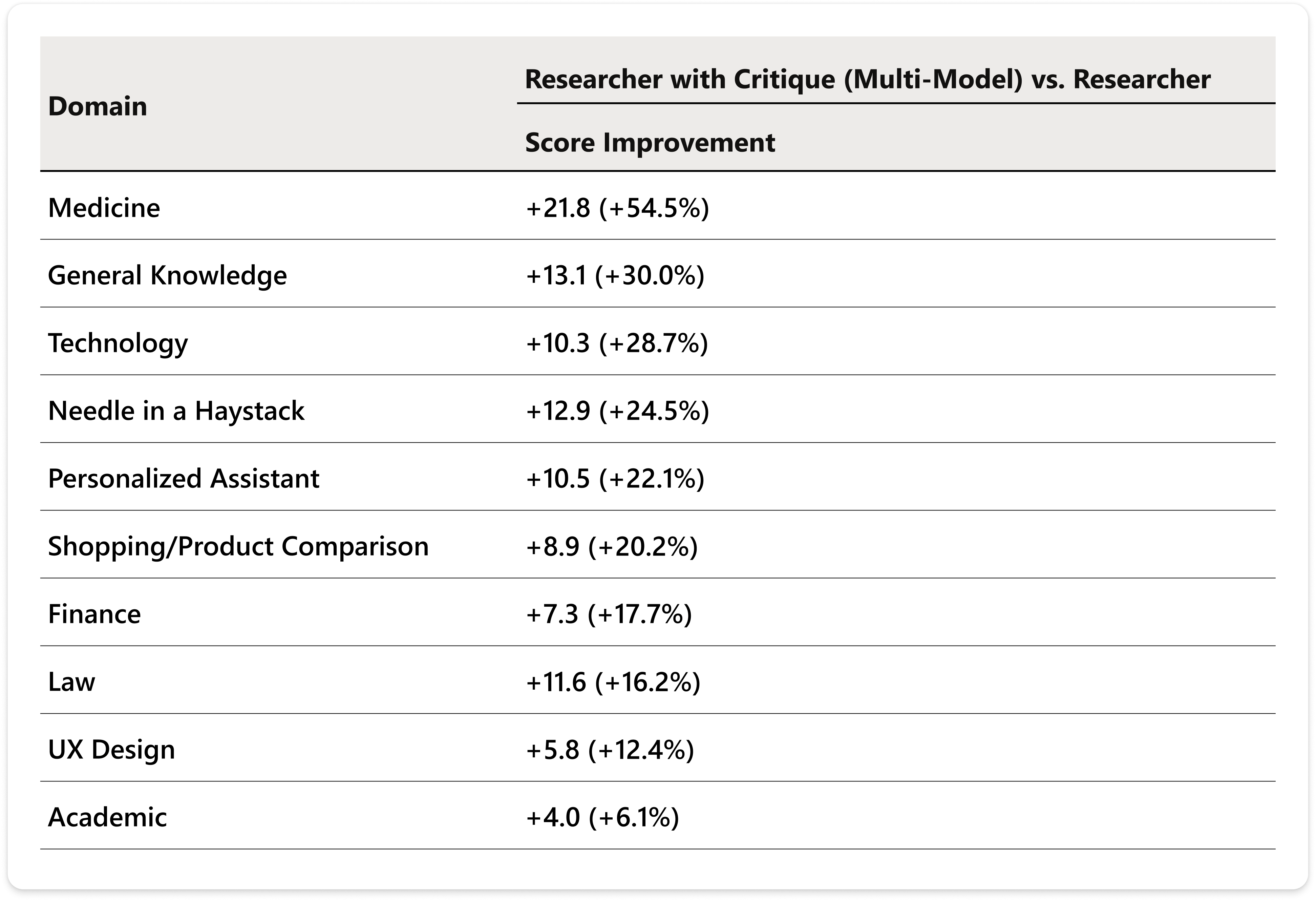
The query set spans domains like medicine, technology, and law, and Microsoft notes that Researcher with Critique scores higher than the single‑model configuration across all ten domains. Eight of those domains show statistically significant improvements (p < 0.05), with Academic and Needle‑in‑a‑Haystack being the only exceptions due to high variance.
Council: side‑by‑side model comparison with a judging layer
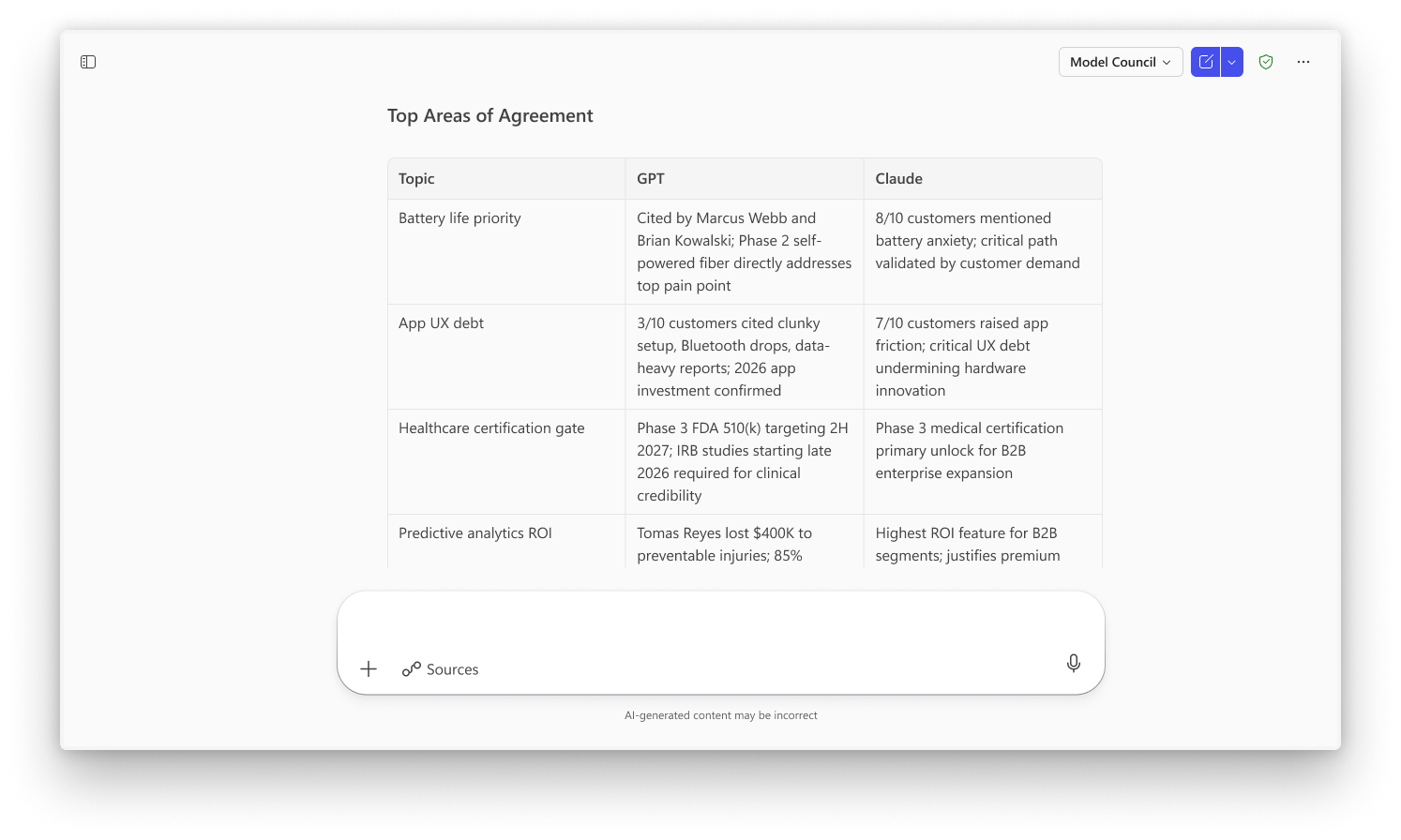
While Critique focuses on a two‑step generator‑reviewer pipeline, Council introduces an alternate mode where multiple models work in parallel. When users choose “Model Council” in the Researcher model picker, an Anthropic model and an OpenAI model each generate their own full report on the same query.
After both reports are produced, a dedicated judge model analyzes them and creates:
-
A distilled summary of the key findings.
-
Highlights of where the models agree and where they diverge—in facts, magnitude, framing, or interpretation.
-
Callouts of unique insights that only one model surfaced.
Council is meant for scenarios where users want to compare perspectives and gain confidence by seeing how multiple high‑end models treat the same research question, rather than relying on a single synthesized answer.
Availability for Frontier customers
Critique and Council are available today in the Frontier program, Microsoft’s early‑access initiative for customers driving large‑scale Copilot and agent adoption. Through Frontier, organizations can start experimenting with multi‑model intelligence in Researcher, incorporating these capabilities into their broader “Frontier transformation” with Microsoft 365 Copilot and agentic workflows.
For knowledge workers who depend on deep research—across domains like medicine, law, technology, and more—these upgrades position Researcher as a more robust, benchmark‑validated alternative to traditional single‑model AI research tools, with a strong emphasis on accuracy, completeness, and transparent evidence.
Recent Posts You Might Like
- How to Easily Update PowerShell on Windows 11 (All Methods: winget, Store, MSI, and Troubleshooting Help Too)
- Xbox Games Showcase 2026 Dated for June 7 With Gears of War: E‑Day Direct and FanFest’s Big Return
- March Xbox Update Brings New Insider Features, Handheld Upgrades, and 1,000+ Cloud Games
- Babylon.js 9.0 Lands With Next‑Gen Lighting, Powerful Tooling, and New Geospatial Engine for the Web
Discover more from Microsoft News Now
Subscribe to get the latest posts sent to your email.
